참고: https://www.youtube.com/watch?v=Rf7wvs8ZbP4
# 자연어 전처리 과정
컴퓨터 및 컴퓨터 언어에서 자연어를 효과적으로 처리할 수 있도록 전처리 과정을 거쳐야한다.
1. 토큰화 ( I/ love/ you)
2. 정제 및 추출(중요한 단어만 남긴다)
3. 인코딩 (0,1로만 이루어진 코딩: 원핫인코딩 OR 정수로 인코딩)
# 언어의 형태소는 중요하다!


# 언어의 전처리 과정

1) 토큰화: 주어진 문장에서 "의미 부여"가 가능한 단위를 찾는다
ex. 어제 삼성 라이온즈가 기아 타이거즈를 5:3으로 꺾고 위닝 시리즈를 거두었습니다.
Q: 5:3을 어떻게 인코딩 할 것 인가? 따로 예외 처리를 해서 수동으로 인코딩을 매겨줘야한다. 5:3으로 묶을 수도 있고, 아니면 콜론을 제거하는 방식도 있을 것이다. --> 이것은 사람의 직관
토큰화가 너무 복잡하니...방법이 없을까? 패키지를 사용하자!
(하지만 단어를 처리하는 방식에 차이가 있으므로 잘 보고 선택해야한다.)
* 표준 토큰화 : Treebank tokenization
* 문장 토큰화: 문장이 매우길때 문장 수준으로 토큰화할 수 있다
2) 정제
1. 대문자 vs. 소문자 (대문자로 남기고 싶은 것은 예외 처리를 해줘야한다)
2. 출현횟수가 적은 단어 제거
3. 길이가 짧은 단어, 지시 대명사, 관사 제거
*희귀한 단어들
ex) Floras and faunas
ex) Protagonist
3) 추출
1. 어간(Stem): 단어의 의미를 담은 핵심
2. 접사(Affix): 단어에 추가 용법을 부여
3. 불용어 제거



4) 인코딩 + Sorting(word2inx 딕셔너리 만들기)
1. 정수 인코딩 (Integer Encoding)
- 중복되는 단어들은 같은 번호
- 중복 안되는 단어들은 다른 번호

1-1. 빈도 기준으로 인코딩 가능하다


2. TF-IDF
- 간단하게!! IDF = A라는 단어가 등장한 문서 수 / 전체 문서 수


왜 idf값에 log를 붙이는가?
https://yeong-jin-data-blog.tistory.com/entry/TF-IDF-Term-Frequency-Inverse-Document-Frequency
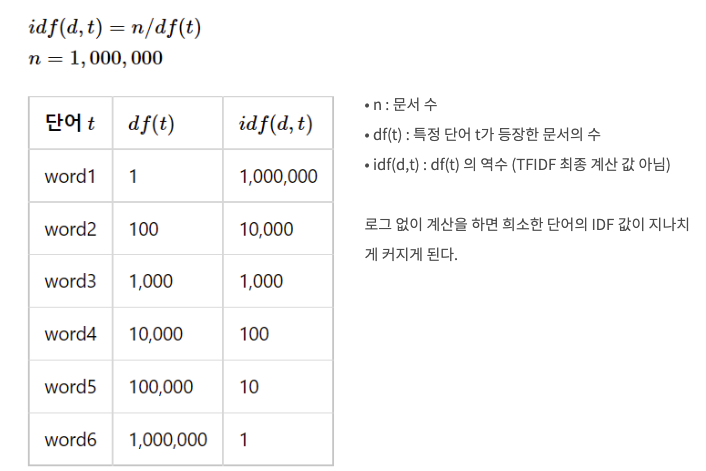

이렇게 log를 붙여서 편차를 줄여주기 위함이다.
3. 원핫 인코딩 (One-hot Encoding)

* 따라서 정수 인코딩을 나중에 원핫으로 바꿔주는 경우 있음 (크로스엔트로피 계산할때 필요함)
4. word2vec
* 정수인코딩으로 커버가 안되는 유사도 문제를 해결해줌
5) Padding (Zero-padding)
- 길이를 맞춥니다 (Zero padding: 0으로 채운다)

'머신러닝 스터디 > 텍스트마이닝' 카테고리의 다른 글
| 토픽모델링 (0) | 2023.11.05 |
|---|---|
| Word Embedding_Word2Vec (0) | 2023.04.28 |
| RNN 단점 보완! GRU/LSTM (0) | 2023.04.22 |
| 자연어 처리 유사도 분석 정리 (0) | 2023.04.22 |
| RNN 작동원리 (0) | 2023.04.22 |